Don’t go blind without Cloud Observability
Time to read: 5 minutes
More years ago than I like to admit, I held an Enterprise Architect position for a regional bank in the Midwest. My areas of focus were storage and disaster recovery.
I was given the task of creating a runbook on how to recover our data center from a full down disaster. This was a huge project where no workload dependencies were documented, no infrastructure dependencies were in a centralized repository, and no one really understood or had categorized what was truly critical to recover in such a situation.
As you’d imagine, it was a bit daunting.
The first challenge I faced was to understand what lines of business to recover, and in what order. Then it was necessary to map those business processes back to the systems and workloads that supported them.
Rather than bore you with a year of my life in excruciating detail, I’ll summarize the two biggest lessons I learned:
- everything is connected to everything,
- everything is critical to someone.
The interdependencies made it such that to recover a minimal viable company from a major disaster required recovery of well over half of the systems and workloads in the data center.
Everything seemed to feed into everything else – but not only that – just as critical as the applications, was the physical infrastructure. The need to understand performance characteristics such that we didn’t put a high-performance workload on a 10 Mb/s network (I told you it was long ago) was just as critical.
And this was for a single data center.

You can’t fix what you can’t see
In those days, there were few tools. Most of the data collected was from in-person interviews with business leaders and other application and infrastructure architects and engineers. I cannot imagine that task today where 24×7 operations are table stakes.
Nowadays workloads are spread across multiple data centers, some under local control, and others in public and managed cloud locations where the ability to affect change may be limited and/or cost prohibitive.
Yet I meet clients all the time and all over the country, doing exactly that, planning their cloud journey functionally blind.
Today there are other options and observability solutions provide the answer.
The best of them will automatically discover your environment and not only give instant insights but include the ability to remediate bottlenecks on the spot.
Given the added layer of complexity a hybrid cloud/multi-cloud environment introduces, I think running without them is like a carpenter showing up for work without a hammer.
Improve observability to smooth your cloud journey
The products I find myself recommending over and again are Turbonomic for infrastructure and Instana for applications and workloads.
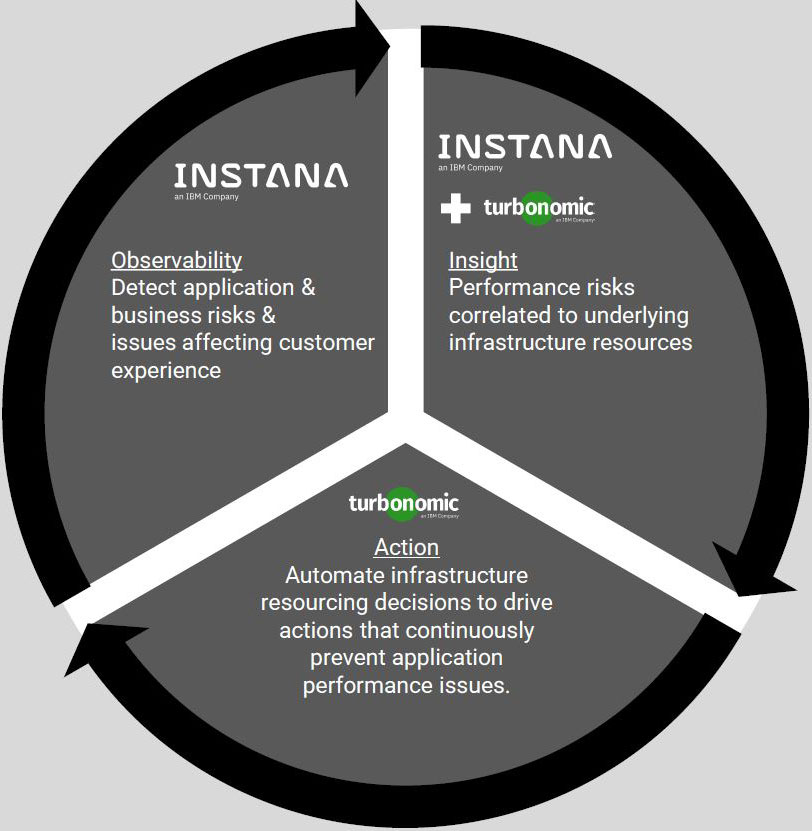
In my opinion, these two applications are best of breed in enabling companies to truly understand how the resources are deployed, where the bottlenecks are, and instantly remediate many instances in real time.
- Cores can be reassigned from over-provisioned systems to ones starving for resources.
- Network resources can be reapportioned on the fly.
- Stranded storage can be instantly identified and given to workloads that are space constrained.
All these benefits, and much more, not only help companies run more efficiently but plan more effectively what workloads should migrate next and to where.
Explore the capabilities of Turbonomic and Instana
These kinds of application resource monitoring (ARM) and observability tools really should be considered critical to the business for any company on a cloud journey, especially if the timelines are aggressive.
We are helping clients realize the benefits and explore the full capabilities through live demonstrations and proof of concepts – as they not only have the ability to save you thousands of dollars, but they are also the literal map you need to make your cloud journey successful.
Explore our legacy application modernization services
Fig 1: Turbonomic infrastructure
Congestion and can happen at every level. Resources driven by ever-change application demand.
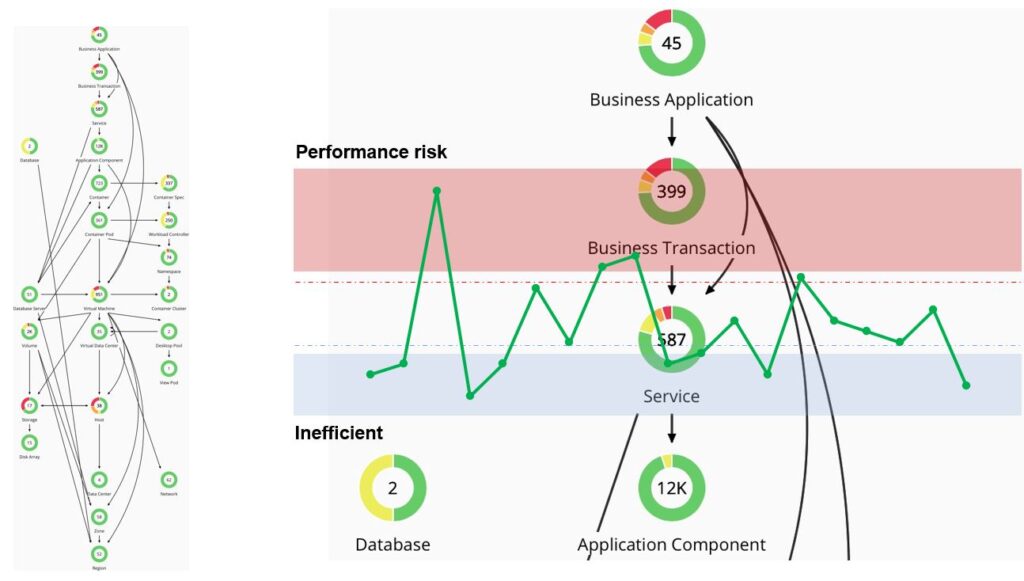
Fig 2: Close-up example of Turbonomic infrastructure
About the author

Read more like this

Storage and Backup
A Buying Guide to Finding the Best Storage Solution for Your Business
Find the right storage solution for your company.

IBM Power
The IT Skills Gap Is Only Getting Wider in 2024
The IT skills gap is forecasted to widen in 2024 – especially for IBM i skills, what happens next?

About Tectrade
Tectrade Change Freeze (Dec-Jan)
We will be operating a ‘Change Freeze’ across our hosted and managed infrastructure to manage risk at this critical time.